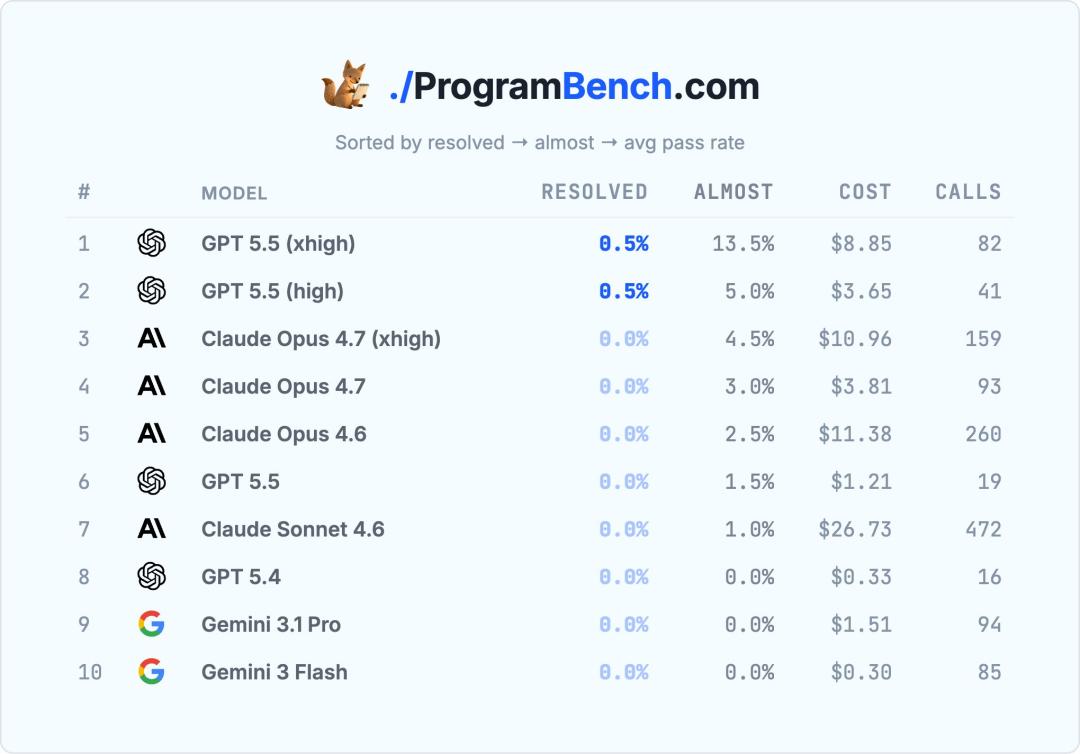
На недавно опубликованном бенчмарке ProgramBench, где ни одна передовая модель до сих пор не могла полностью решить ни одной задачи, модель GPT-5.5 впервые прошла одну задачу «с нуля» — без исходников, без декомпиляции и без доступа к сети.
Этот успех подчёркивает, что для задач программирования ключевым фактором становится не только архитектура модели, но и доступные ей режимы глубокой/долгой интуиции (high, xhigh).
ProgramBench — новый, строгий бенчмарк программирования, предложенный Meta (запрещённой в России) совместно со Стэнфордом и Гарвардом. В отличие от традиционных тестов вроде SWE-bench или HumanEval, где модели чаще «исправляют» уже существующий код (открытый или полуу́казанный контекст), ProgramBench ставит задачу полностью восстановить программу по двоичному исполняемому файлу и документации:
200 задач: от небольших утилит (jq, ripgrep) до тяжеловесов типа FFmpeg, SQLite, PHP-compiler.
Проходность при запуске: 0% — ни одна модель не могла полностью решить хоть одну задачу.
Ограничения: исходники не предоставляются; декомпиляция и сетевой доступ запрещены.
Этот формат делает оценку максимально «закрытой» и проверяет способность модели реконструировать поведение программы «с нуля».
Первая задача, решённая GPT-5.5, — классическая утилита cmatrix (эффект «цифрового дождя» из «Матрицы»). Примечательно, что при двух уровнях high и xhigh модель выбрала разные языки:
high — реализация на C. Стратегия: сначала 10 раундов исследования (40+ вариантов флагов) для полного понимания CLI-поведений, затем одна крупная реализация и 5 исправляющих итераций.
xhigh — реализация на Python. Глубже — 27 шагов исследования, покрыты все ветви CLI, затем готовая Python-реализация.
Обе реализации прошли полный набор тестов поведения.
Ключевые цифры:
В режиме medium GPT-5.5 показал лишь небольшое улучшение над конкурентами.
В режиме xhigh модель резко выстрелила: впервые задача с проходностью 0% оказалась решена (прибл. 0.5% от выборки), при этом 26 задач были «почти решены» (более 95% юнит-тестов).
На гистограмме накопленной производительности GPT-5.5 xhigh опережал всех соперников по среднему, медиане и доле задач с ≥90% прохождением.
В том же эксперименте Claude Opus 4.7 в режиме xhigh показала более слабые результаты и допускала грубые системные ошибки, несмотря на большие вычислительные и API-затраты:
Opus 4.7: 178 вызовов API, стоимость ≈ $10.74, 19 проваленных тестов.
GPT-5.5 (стандартная конфигурация): 17 вызовов, ≈ $1.04.
Две фундаментальные ошибки Opus:
Чувствительность к регистру при разборе цвета — использована strcmp() вместо нечувствительной strcasecmp(); входы типа GREEN/Red/BLUE неправильно распознавались → 11 тестов провалено.
Неправильный код выхода для невалидного цвета — вместо exit(0) реализован exit(1) → 8 провалов.
Интересный момент: Opus продемонстрировала высокий уровень инженерной инициативы при проблеме с отсутствием ncurses.h: вместо упрощённого перехода на ANSI-escape, как другие модели, она провела ~20 шагов системного анализа (ldconfig -p, nm -D) и вручную сгенерировала 106-строчный заголовок, чтобы связать динамическую библиотеку — впечатляющая, но не решающая вкладка в итоговом счёте.
ProgramBench ясно показал, что классические бенчмарки «тают»: многие eval-метрики (SWE-bench, GPQA) уже показывают очень высокие проходные проценты, и различать модели становится труднее. ProgramBench ввёл новую точку отсчёта — задачи, требующие фактически «собрать» поведение программы без подсказок.
Решение одной из задач ProgramBench моделью GPT-5.5 — важная веха: она демонстрирует практическую разницу между «быстрой подсказкой» и «длинным» интеллектуальным исследованием.
Если тренд на увеличение продолжится, в ближайшие итерации можно ждать новых «прорывов», которые будут смещать границы того, что ИИ может воссоздавать и автоматизировать в области программной инженерии.