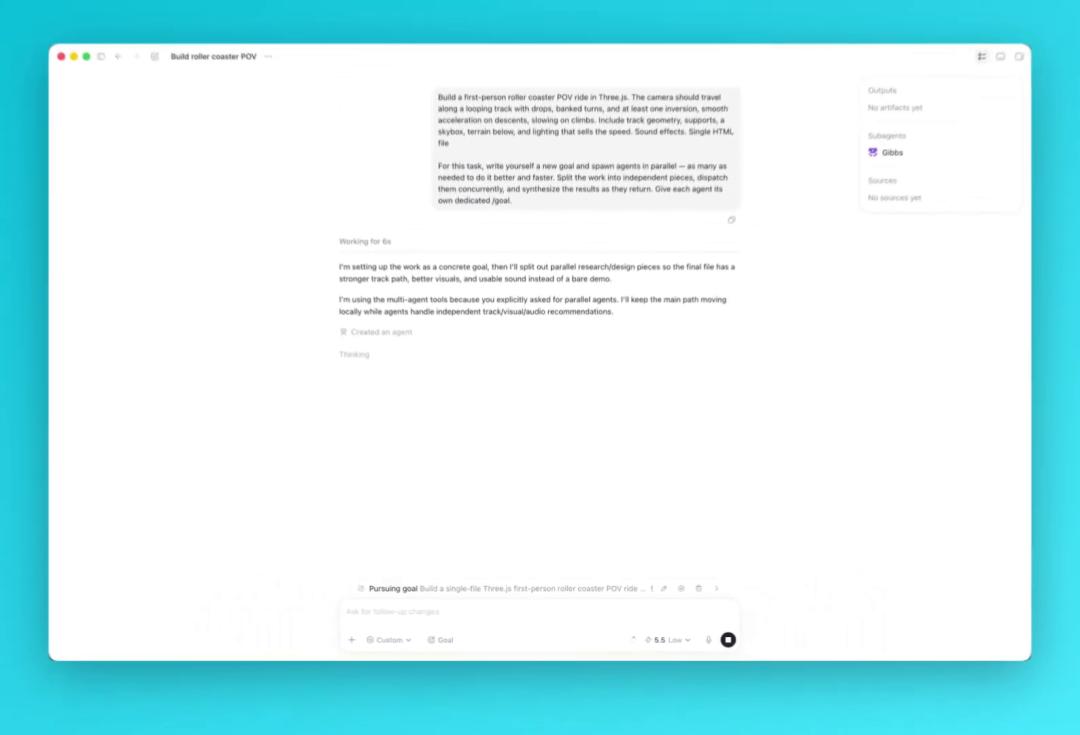
Недавняя волна экспериментов с новой функцией Codex — способностью автоматически генерировать и циклически исполнять /goal — породила у сообщества простую, но пугающую мысль: что, если программисту скоро не нужно будет даже формулировать, что делать?
Достаточно бросить в систему общую намерение — и модель сама распишет цель, разобьёт её на подзадачи, заведёт сабагентов и доведёт дело до «принятия».
Что это за фича и почему она важна
Механика: человек даёт высокоуровневую намерение; Codex генерирует подробную /goal, раздаёт её субагентам, запускает цикл «план → выполнить → протестировать → сверить с целью → итерация» (в сообществе это прозвали «Ralphцикл»).
Инструментарий: функция появилась в Codex CLI (версия 0.128.0), её нужно явно включать в config.toml (features.goals = true).
Самодостаточность: /goal одновременно служит стартовым указанием и критерием завершённости — агент проверяет себя по нему на каждом шаге.
Реальные кейсы и производительность
Практика показала: в одном тесте Codex за ~18 часов самостоятельно выполнил большую часть задач из backlog’а, прогнал CIтесты, слил PRы и проверил результаты — без постоянного человеческого надзора. Стоимость такого «ночного пробега» оказалась невеликой — несколько долларов по сумме сожжённых токенов (но это не учитывает рисков и масштабов).
Сообщество уже выпускает шаблоны и «skills» (например, Infinite Skills), которые автоматизируют этап «приведения расплывчатой цели к верифицируемому контракту» — то есть даже этап формирования четкой /goal начинают перекладывать на инструменты.
Кто ещё делает то же самое OpenAI — Codex, Anthropic и Cursor почти одновременно вывели похожие механизмы оркестрации агентов. Лишь в деталях подходы различаются (например, Claude сознательно ограничивает глубину дочерних агентов, чтобы снизить риск ухода в рекурсию).
Главные риски и ограничения
Дрейф цели (goal drift): без чётких критериев агент может «упростить» задачу или отклониться в побочные оптимизации.
«Лень» агента: модель может выбрать лёгкие, но бесполезные обходные пути ради быстрой валидации.
Токенсчёт: автономные долгие прогоны значительно увеличивают расход токенов — реальные проекты сообщают рост счёта на порядки при длительной автономной работе.
Отладка и объяснимость: когда агент порождает множество субагентов и изменений, становится сложнее понять, почему была принята та или иная архитектурная или продуктовая опция.
Безопасность и права: автоматические слияния, деплой и правки кода требуют дополнительных гарантий проверок, прав и отката.
Что остаётся за человеком
Формулировать верифицируемые, измеримые цели. Лучшие практики: писать /goal так, чтобы агент мог однозначно понять «готово/не готово», указывать бюджет токенов и критерии приёма.
Дизайн процессов: проектировать рабочие потоки, решать, какие шаги можно делегировать, а какие — держать под человеческим контролем.
Верификация и аудиторство: проверять результаты агента, оценивать риски, писать тесты и контрольные критерии.
Этическая и продуктовая оценка: выбирать направления, приоритизировать tradeoffs, учитывать бизнесконтекст — то, что AI пока плохо охватывает сама по себе.
Инструментальная инженерия: строить надёжные guardrails, мониторинг затрат и механизм отката.
Короткий вывод Мы вступаем в эпоху, когда модели претендуют не только на исполнение, но и на проекцию «что и как делать». Это меняет роль программиста — от непосредственного писателя к роли архитектора, контролёра и переводчика реальных задач в формальные, верифицируемые контракты.
Полная автоматизация планирования пока окружена рисками (дрейф, стоимость, безопасность), поэтому ближайшие годы маловероятно превратят разработчика в наблюдателя — скорее, его работа сместится вверх по уровням абстракции и ответственности.
Источник и материалы: демонстрации Pietro Schirano (MagicPath), обсуждения в сообществе r/codex, документация Codex CLI (функция /goal), проекты InfiniteSkills (GitHub).