Обработка естественного языка (NLP): Технологии и методы NLP
Обработка естественного языка (NLP, Natural Language Processing) — это область искусственного интеллекта, которая занимается взаимодействием между компьютерами и человеческим языком. Основная цель NLP — сделать так, чтобы компьютеры могли понимать, интерпретировать и генерировать человеческий язык. Технологии и методы NLP широко применяются в таких областях, как автоматический перевод, чат-боты, анализ тональности, и многие другие. В этой статье мы рассмотрим основные технологии и методы, которые лежат в основе современной NLP.
1. Основные задачи NLP
1.1. Токенизация
Токенизация — это процесс разбиения текста на более мелкие единицы, называемые токенами. Токены могут быть словами, предложениями или символами. Это первый шаг в большинстве NLP задач.
Примеры токенизации:
1.2. Часть речи (POS) тэггинг
POS-тэггинг — это процесс определения грамматической категории (части речи) для каждого токена в предложении. Это помогает моделям понять синтаксическую структуру текста.
Пример:
1.3. Распознавание именованных сущностей (NER)
NER — это задача определения и классификации именованных сущностей в тексте, таких как имена людей, названия мест, даты и организации.
Пример:
1.4. Анализ синтаксиса (Parsing)
Синтаксический анализ включает построение синтаксического дерева для предложения, которое показывает его грамматическую структуру.
Пример:
1.5. Анализ тональности (Sentiment Analysis)
Анализ тональности — это задача определения эмоциональной окраски текста. Это может быть полезно для анализа отзывов, комментариев в социальных сетях и других текстовых данных.
Пример:
1.6. Машинный перевод
Машинный перевод включает автоматическое преобразование текста с одного языка на другой. Современные модели, такие как трансформеры, сделали значительные успехи в этой области.
Пример:
1.7. Генерация текста
Генерация текста — это создание нового текста на основе заданного входа. Модели генерации текста могут использоваться для создания статей, ответов на вопросы, генерации диалогов и других приложений.
Пример:
2. Технологии и методы NLP
2.1. Традиционные методы NLP
2.1.1. Регулярные выражения
Регулярные выражения (Regular Expressions, Regex) — это мощный инструмент для поиска и манипуляции текстом. Они позволяют описывать шаблоны текстов, которые нужно найти или заменить.
Пример:
2.1.2. Бэг слов (Bag of Words, BoW)
Бэг слов — это простая модель, которая представляет текст как множество слов без учета порядка. Каждый текст представляется в виде вектора, где каждое измерение соответствует количеству вхождений определенного слова в тексте.
Пример:
2.1.3. TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) — это статистический метод, который оценивает важность слова в документе относительно всего корпуса. TF-IDF помогает выделить значимые слова, исключая часто встречающиеся, но не информативные термины.
Пример:
2.2. Современные методы NLP
2.2.1. Word Embeddings
Word Embeddings — это представления слов в виде плотных векторов в непрерывном пространстве. Они позволяют моделям захватывать семантические и синтаксические отношения между словами.
Популярные модели:
Пример:
2.2.2. Модели на основе внимания (Attention Mechanisms)
Механизм внимания позволяет модели фокусироваться на различных частях входной последовательности при генерации каждого элемента выходной последовательности. Это особенно полезно в задачах машинного перевода и генерации текста.
Пример:
2.2.3. Трансформеры (Transformers)
Трансформеры — это архитектура, основанная на механизме внимания, которая позволяет параллельно обрабатывать всю входную последовательность. Это делает их более эффективными и мощными по сравнению с RNN и LSTM.
Пример:
2.2.4. Предварительно обученные языковые модели
Предварительно обученные языковые модели, такие как BERT и GPT, обучаются на больших объемах текста и затем дообучаются на конкретных задачах. Эти модели значительно улучшили качество многих NLP задач.
Примеры:
2.2.5. Fine-tuning
Fine-tuning — это процесс дообучения предварительно обученной модели на конкретной задаче или наборе данных. Это позволяет улучшить производительность модели для конкретных приложений.
Пример:
3. Применения NLP
3.1. Чат-боты и виртуальные ассистенты
Чат-боты и виртуальные ассистенты, такие как Siri, Alexa и Google Assistant, используют NLP для понимания и генерации естественного языка. Они помогают пользователям выполнять задачи, отвечать на вопросы и предоставлять информацию.
3.2. Машинный перевод
Системы машинного перевода, такие как Google Translate, используют модели NLP для автоматического перевода текста с одного языка на другой. Современные модели, такие как трансформеры, значительно улучшили качество перевода.
3.3. Анализ тональности
Анализ тональности используется для определения эмоциональной окраски текста. Это полезно для анализа отзывов клиентов, комментариев в социальных сетях и других текстовых данных. Модели NLP помогают компаниям лучше понимать мнения и настроения пользователей.
3.4. Обобщение текста
Обобщение текста включает создание краткого и информативного резюме из большого текста. Модели NLP помогают автоматизировать этот процесс, что полезно для анализа новостей, отчетов и других длинных документов.
3.5. Named Entity Recognition (NER)
NER используется для автоматического извлечения именованных сущностей из текста. Это полезно для анализа документов, статей и других текстовых данных, чтобы извлекать информацию о людях, местах, организациях и других важных сущностях.
3.6. Автоматическое дополнение текста
Автоматическое дополнение текста, используемое в системах типа автозаполнения, помогает пользователям быстрее и точнее вводить текст. Модели NLP предсказывают следующие слова или фразы на основе контекста.
Примеры кода для обучения NLP моделей
1. Токенизация с использованием библиотеки NLTK
NLTK (Natural Language Toolkit) — одна из самых популярных библиотек для обработки естественного языка в Python.
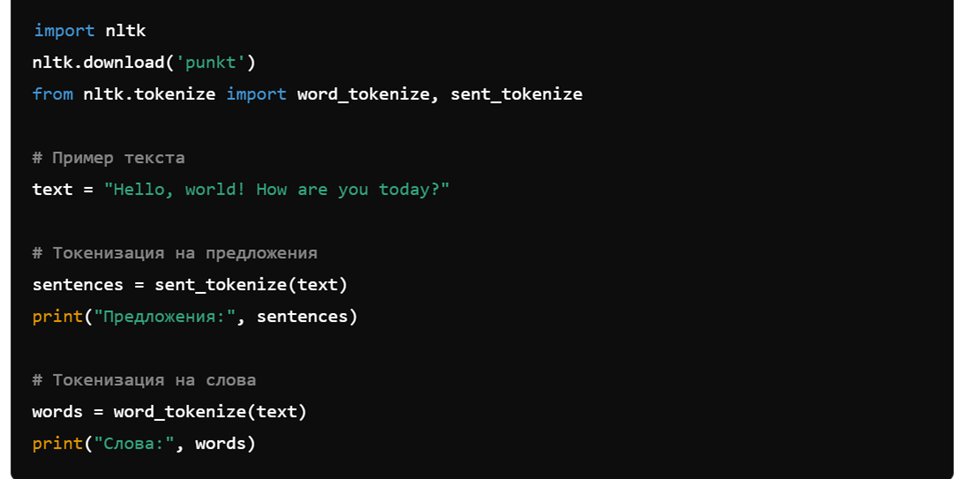
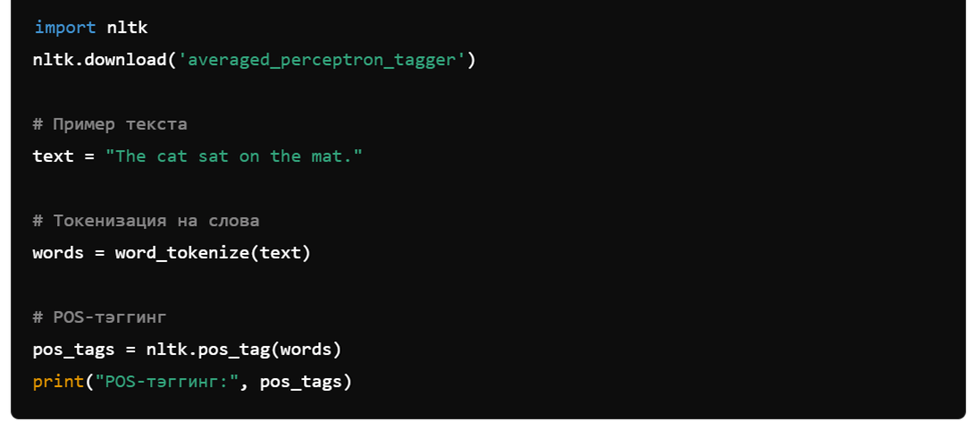
2. Часть речи (POS) тэггинг с использованием NLTK
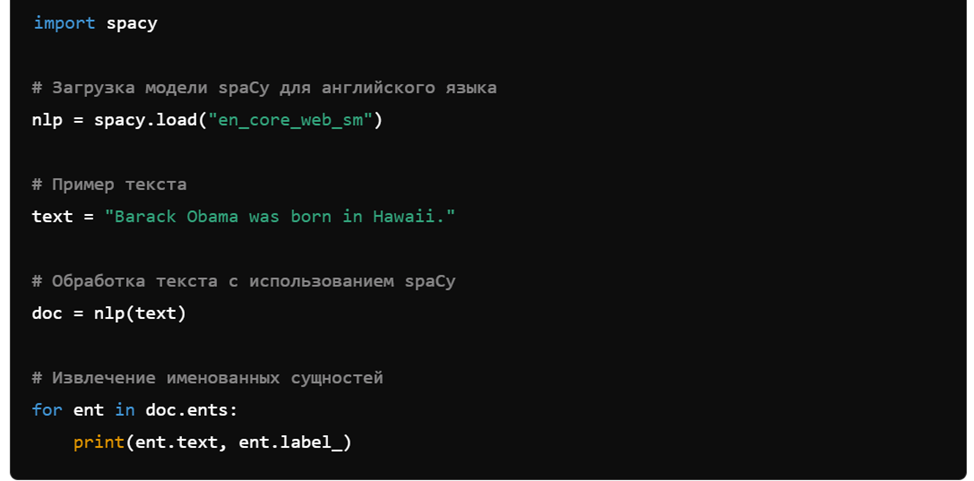
3. Распознавание именованных сущностей (NER) с использованием spaCy
spaCy — мощная библиотека для NLP, обеспечивающая поддержку различных задач, включая NER.
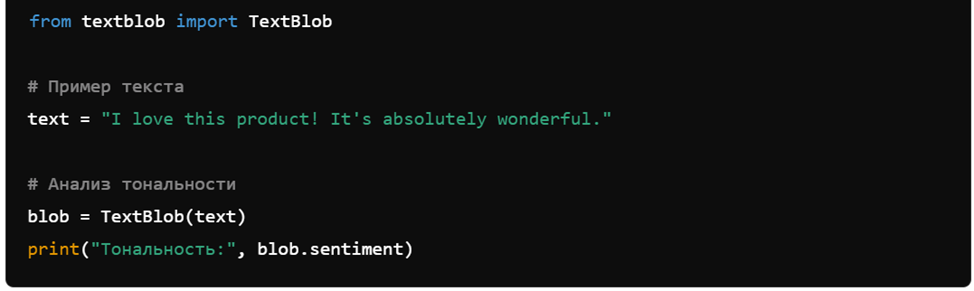
4. Анализ тональности с использованием TextBlob
TextBlob — простая библиотека для NLP, предоставляющая инструменты для анализа тональности.
5. Машинный перевод с использованием библиотеки transformers
Transformers — библиотека от Hugging Face для работы с трансформерами и моделями NLP.
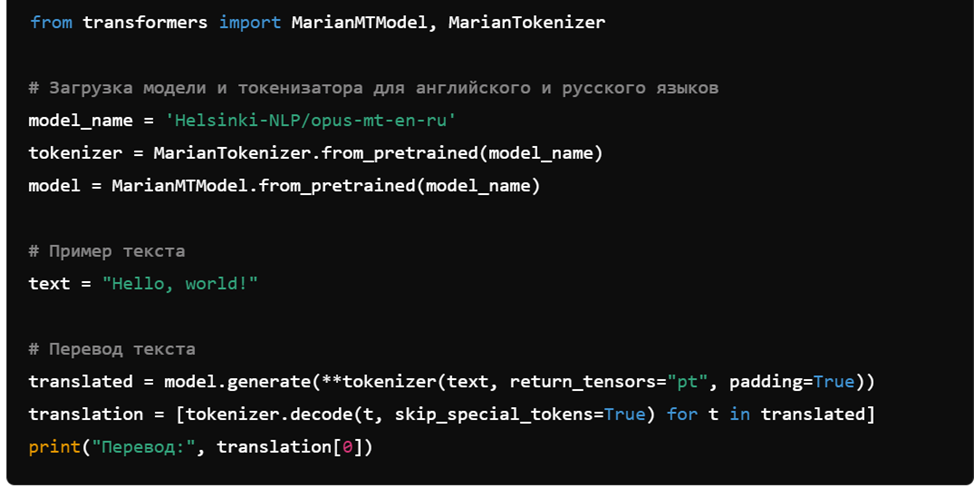
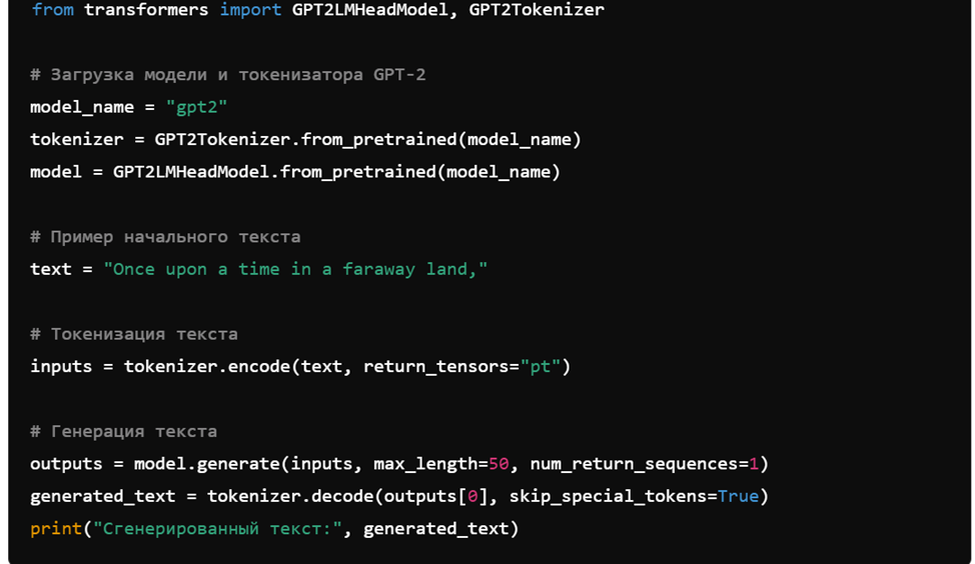
6. Генерация текста с использованием модели GPT-2
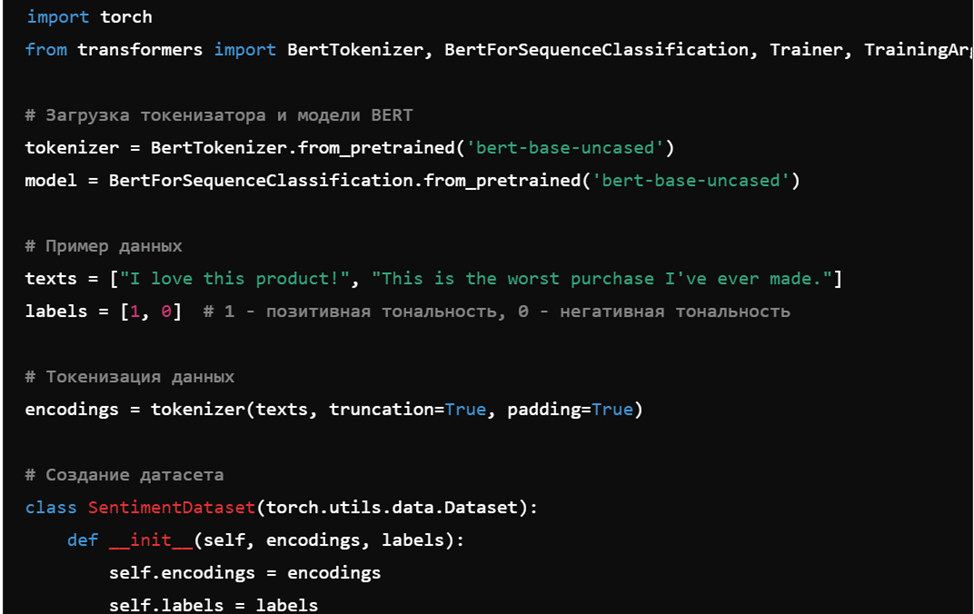
7. Дообучение модели BERT для классификации текста
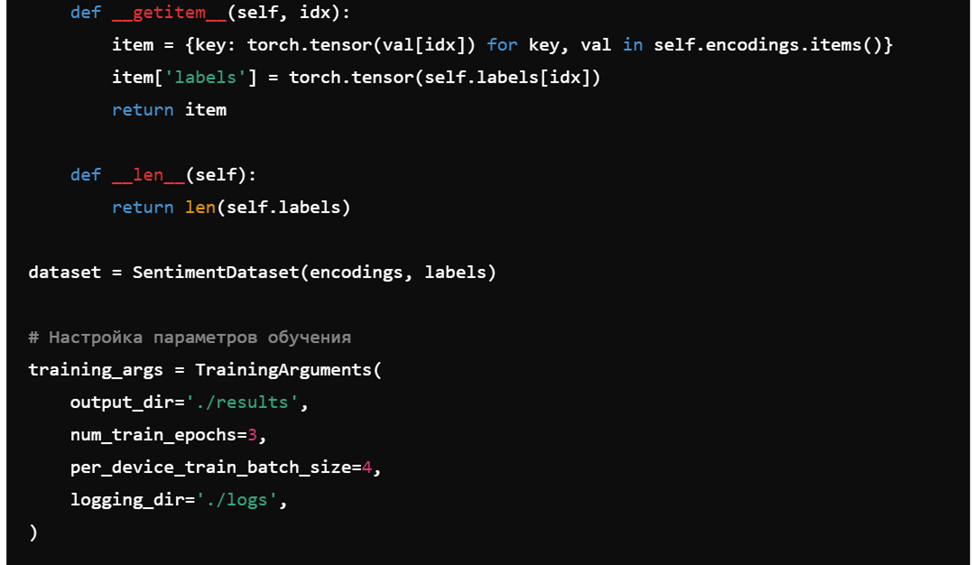

Эти примеры кода демонстрируют основные методы и технологии NLP, от токенизации и POS-тэггинга до анализа тональности и дообучения моделей. Они помогут вам начать работу с различными задачами обработки естественного языка и использовать современные инструменты и библиотеки для достижения высоких результатов.
Заключение
Обработка естественного языка (NLP) продолжает развиваться и улучшаться, открывая новые возможности для взаимодействия человека и компьютера. Традиционные методы, такие как токенизация, POS-тэггинг и TF-IDF, дополняются современными подходами, такими как трансформеры и предварительно обученные языковые модели. Благодаря этим достижениям, NLP находит все большее применение в различных областях, от чат-ботов и машинного перевода до анализа тональности и обобщения текста. С развитием технологий и увеличением объемов данных можно ожидать появления новых, еще более мощных методов и моделей NLP, которые продолжат революционизировать нашу повседневную жизнь.