Очередной, казалось бы, простой вопрос снова поставил большие языковые модели в тупик. Пользователь задал AI такой сценарий: «Я хочу помыть машину, мой дом находится всего в 50 метрах от автомойки. Что лучше — идти пешком или ехать на машине?»
Ответ кажется очевидным человеку: если вы хотите помыть машину, то автомобиль нужно привезти на автомойку, а не идти туда пешком. Но большинство моделей рассудили иначе. Они советовали пройтись пешком, потому что расстояние маленькое, это полезнее, быстрее и экологичнее.
Так обычный бытовой вопрос превратился в интернет-мем, а затем — в серьёзный исследовательский кейс, который показал важную слабость современных LLM: они часто цепляются за самый заметный признак, игнорируя скрытое условие задачи.
Вопрос задали сразу нескольким крупным моделям. Результат оказался печальным:
ChatGPT предложил идти пешком;
DeepSeek тоже посоветовал не ехать на машине;
Kimi настаивал на прогулке;
Qwen даже привёл «рациональные» аргументы, почему пешком лучше.
Лишь немногие модели, например Gemini, сразу поняли подвох и ответили примерно так: «Если только у вас нет способности мыть машину на расстоянии, лучше ехать на ней».
Проблема оказалась не в отсутствии знаний. Почти все модели знают, что машину нужно привезти на мойку. Но в момент ответа они в первую очередь реагируют на число “50 метров”, а не на смысл задачи. Иными словами, они видят не «помыть машину», а просто «сходить в ближайшее место».
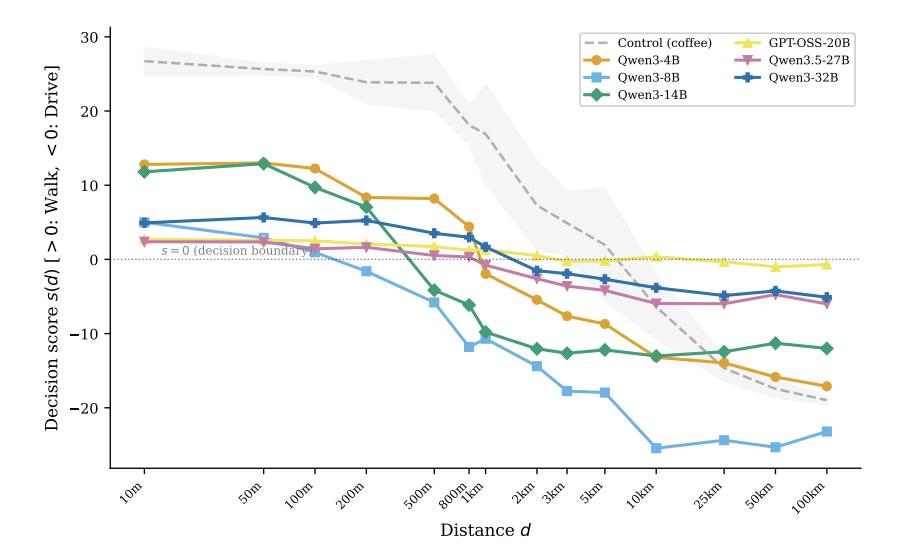
Исследователи из Carnegie Mellon University решили разобрать этот феномен системно. Они показали, что проблема не в одной конкретной формулировке, а в более общем механизме: поверхностные подсказки вытесняют скрытые ограничения.
В их работе этот эффект описан как ситуация, когда модель сильнее реагирует на очевидный признак, чем на самую суть запроса. В случае с мойкой автомобиля таким признаком становится короткое расстояние. Модель делает вывод: раз рядом — значит, идти пешком.
Но человек понимает, что у задачи есть неявное условие: машина должна быть при вас. Без этого условия идти пешком бессмысленно.
Учёные протестировали несколько open-source моделей и обнаружили, что в исходной формулировке задачи они практически все ошибались. Затем был проведён более широкий тест на сотнях вопросов, где проверялись разные типы скрытых ограничений:
наличие объекта;
возможность действия;
корректный диапазон;
соответствие цели;
логическая совместимость шагов.
Результат оказался тревожным: даже очень сильные модели часто попадались на простые ловушки.
Исследователи также обнаружили, что если убрать конфликтующее условие, многие модели начинают отвечать «правильно», но это не обязательно означает настоящее понимание. Иногда модель просто выбирает более вероятный или более безопасный ответ по шаблону.
Причина в том, как устроено их обучение. LLM не «понимают» мир так, как человек. Они не имеют тела, не переживают физический опыт и не знают, что значит реально стоять у дома с ключами от машины. Они обучены на огромных массивах текста, где очень часто встречается паттерн:
если расстояние маленькое — лучше идти пешком;
если задача простая — не усложняй;
если объект рядом — не надо ехать.
Этот шаблон настолько силён, что перебивает скрытый смысл задачи.
Для человека фраза «я хочу помыть машину» автоматически активирует целый набор неявных предположений:
машина есть рядом;
её нужно везти;
автомойка не моет автомобиль на расстоянии;
идти пешком — не то же самое, что подъехать на машине.
У модели такого слоя бытовой интуиции нет. Она работает через статистические связи между токенами, а не через жизненный опыт.
Этот кейс важен не потому, что он смешной. А потому, что он показывает фундаментальную границу между правдоподобным ответом и реальным пониманием.
Современные модели умеют:
рассуждать длинными цепочками;
находить аргументы;
исправлять свои ошибки после подсказки;
звучать очень убедительно.
Но при этом они всё ещё могут провалиться на задаче, где нужно просто не забыть, что автомобиль нельзя мыть, если его не привезли на автомойку.