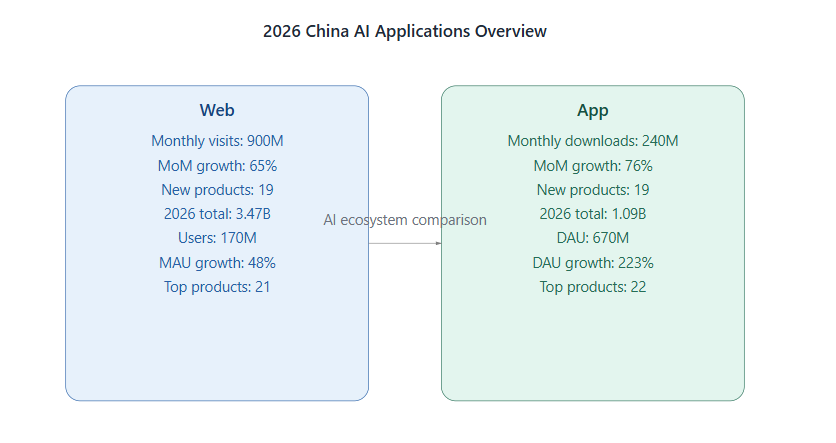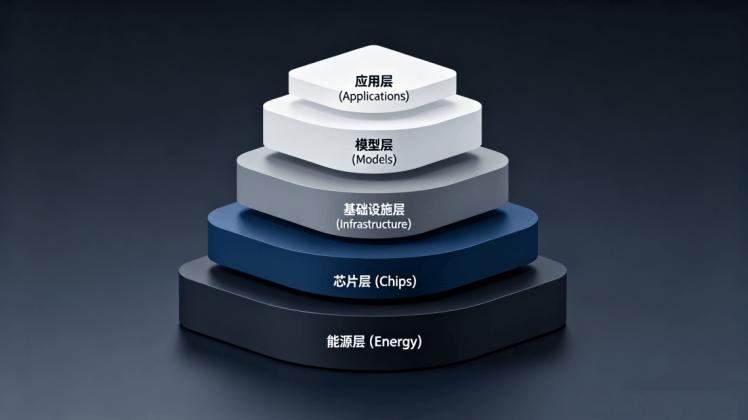
История вокруг отношений NVIDIA и китайского рынка в 2026 году всё меньше похожа на спор о поставках «железа» и всё больше — на спор о том, кто быстрее построит самодостаточную технологическую систему. Показательны два эпизода с участием основателя NVIDIA Дженсена Хуана: сначала — его демонстративно уклончивый ответ на вопрос журналистов о возможных продажах чипов Huawei, затем — резкая реакция в подкасте на призывы «полностью перекрыть» доступ Китая к передовым ускорителям. Логика Хуана проста и неприятна для сторонников жёсткого запрета: масштаб китайского AI-сообщества велик, а запреты не «останавливают», а вынуждают — и Китай действительно способен построить альтернативу. В начале 2026 года Хуан предложил метафору «пятислойного пирога», описывая, из чего на самом деле состоит конкурентоспособность в ИИ: Энергия — фундамент: без дешёвой и стабильной электроэнергии никакая модель не будет экономически жизнеспособной. Чипы — двигатель: ускорители превращают энергию в вычисления, определяя эффективность обучения и инференса. Инфраструктура — «тело» системы: дата-центры, охлаждение, сети и коммуникации, позволяющие масштабировать кластеры. Модели — алгоритмическая «надстройка»: большие модели, мультимодальность, оптимизации. Приложения — верхний слой и конечная цель: робототехника, автопилот, промышленность, медицина — всё, что превращает ИИ в производительность и деньги. Ценность этой рамки в том, что она переводит разговор из плоскости «у кого быстрее GPU» в плоскость системной кооперации слоёв. И одновременно подсвечивает слабость экспортных ограничений: они относительно эффективно давят лишь на второй слой (чипы), тогда как оставшиеся четыре могут развиваться и «подтягивать» систему вверх. По приведённым в материале примерам, давление на технологические поставки началось задолго до бума больших моделей: ограничения на оборудование, расширение санкционных механизмов, переход от точечных списков к более широким барьерам. Для NVIDIA это обернулось почти полной остановкой высокомаржинального сегмента в Китае. Но побочный эффект оказался тем самым «обратным ускорителем», о котором говорил Хуан: чем сильнее «перекрывают», тем быстрее появляются стимулы и бюджеты на собственные решения. В результате китайские производители AI-чипов ускоряют итерации продуктов (по тренду — больше производительность, крупнее кластеры, лучше программная совместимость), а экосистема продолжает расширяться новыми анонсами. Однако даже если по «сырой» мощности отдельные решения пока уступают лидерам, Китай начинает выигрывать в системе слоёв. Энергия. Избыток энергии частично компенсирует отставание в чипах. У Китая — очень высокая генерация электроэнергии и, по приведённым оценкам, меньшая доля потребления дата-центрами относительно общего энергобаланса, чем у США. Проекты вроде «данные на востоке — вычисления на западе» дополнительно играют на снижении стоимости обучения за счёт регионов с более дешёвой электроэнергией и «зелёными» источниками. Инфраструктура. Гонка ИИ — это не только GPU, но и охлаждение, плотность размещения, стабильность сетей. Материал приводит пример ускоренного развития жидкостного охлаждения и импортозамещения компонентов (в частности, охлаждающих жидкостей), что укрепляет самостоятельность инфраструктурного слоя. Модели. Здесь важна не только «наука», но и массовость: по данным из материала, доля скачиваний китайских open-source моделей на Hugging Face в марте 2026 года достигла 41% (впервые превысив показатель США 36,5%). В качестве примера упоминается экосистема Qwen с огромным количеством производных моделей и масштабом сообщества. Это означает, что конкурентоспособность всё меньше привязана к единственной аппаратной платформе — её начинает «таскать» за собой софт и комьюнити. Приложения. Самый «земной» слой, и, по логике материала, сильнейший китайский аргумент: высокая проникновенность AI в медицине, производстве и финансах создаёт постоянный спрос на вычисления. Этот спрос, в свою очередь, поддерживает рынок локальных ускорителей: чем больше внедрений — тем больше закупок, тем больше стимулов оптимизировать софт под отечественное железо. Переломный момент связан с тем, что DeepSeek V4 (preview) показал глубокую адаптацию под отечественные платформы, включая Huawei Ascend. Смысл этого события не в одной модели, а в том, что оно «ломает» историческую аксиому отрасли: будто бы топовый ИИ неизбежно должен работать внутри экосистемы CUDA. Именно здесь проявляется главная «крепость» NVIDIA: не только GPU как продукт, а связка GPU + CUDA + инструменты + библиотеки + привычки миллионов разработчиков. Поэтому реальная борьба — за миграцию разработчиков и за накопление «капитала экосистемы»: операторов, компиляторов, библиотек, оптимизированных операторов, отраслевых моделей, отладочных инструментов. Когда появляется связка «топовая модель + отечественные ускорители + собственный программный стек», начинается самоподдерживающийся цикл. Каждый разработчик, ушедший с CUDA, уносит часть «липкости» старой платформы — и добавляет ценности новой. По оценке, у Ascend — около 4 млн разработчиков, что формирует эффект «головной стаи» для всей отечественной AI-экосистемы. Технологическая блокада редко убивает инновации — чаще она перерисовывает карту конкуренции. В логике «пятислойного пирога» запреты бьют по чипам, но ускоряют работу по остальным слоям: энергии, инфраструктуре, моделям и приложениям. Именно в этой системе Китай получает шанс не «догнать», а со временем вырастить собственную траекторию — где CUDA остаётся сильной, но уже не единственной возможной средой обитания передового ИИ.